
NVIDIA RTX 5070 Ti 16GB首发评测!AI全升级,好意思满中高端转机
写在开首
不知说念前段时辰屏幕前的你抢到了GeForce RTX 5090D或GeForce RTX 5080没呢?旗舰级的显卡代表极致的性能剖析,但更多玩家追求的是性能开释实足优秀的同期,还大约有性价比的订价。因此RTX 50系的70级显卡来了!照旧纯属的滋味,全新做事器级别的Blackwell架构,TSMC N4工艺打造,还有DLSS 4、Reflex 2等诸多黑科技集于安静孤身一人!率先推出的则是GeForce RTX 5070 Ti显卡。

比较可惜,这一级别的显卡NVIDIA并莫得筹画推出FE公版遐想,而是全由AIC厂商来把控。看过咱们GeForce RTX 5080 FE评测的玩家齐知说念,其银黑相间而又工致浮薄的遐想,妥妥的性能黑武士。不外不要害,本次测试将会使用NVIDIA提供的影驰GeForce RTX 5070 Ti魔刃。一样是玄色的遐想,一样的SFF READY尺度遐想,况兼电竞作风十足。即使你不心爱玄色的显卡,影驰也为咱们提供了白色版块的影驰GeForce RTX 5070 Ti圣刃。

事不宜迟,就让咱们往下望望GeForce RTX 5070 Ti能否引颈更极致的性能剖析!再现70级显卡荣光!
规格先容
运转前,照例讲讲新显卡的规格。GeForce RTX 50系显卡选拔了此前NVIDIA在AI领域推出的Blackwell架构,以大卫·布莱克威尔定名,其是又名受东说念主尊敬的数学家和统计学家,在博弈论和统计学领域留住了不行隐藏的孝敬,NVIDIA用其名字定名这一架构反应了新平台的创始性和先进的筹画能力。Blackwell不错说是NVIDIA比年来更新幅度最大的GPU架构了,比拟起之前的架构来说,划期间地引入了神经集会着色器,力争为游戏创始先进、高效更有传神的渲染方法,带给玩家全新的游戏体验。

比拟前代Ada架构,Blackwell的升级聚焦于四大标的:鉴别是AI算力的爆发、光芒跟踪时刻的鼎新、显存能效的擢升以及划期间的神经集会渲染。
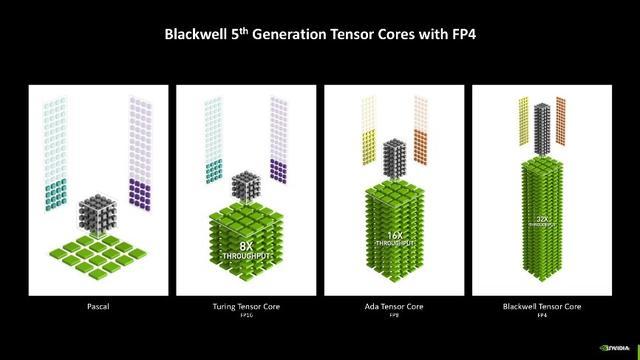
第五代Tensor Core
其中AI算力的爆发就不得不提到Blackwell架构上的第五代,新一代Tensor Core添加了对FP4浮点运算精度的赞助。FP4是一种较低的量化方法,雷同于文献压缩,不错减小模子推理经由中数据存储和筹画量大小,提高筹画效率,镌汰该经由对显存的要求。与大多数模子默许使用的FP16比拟,FP4使用的显存不到其一半,并使GeForce RTX 50系列GPU的性能比拟上一代擢升高达2倍。

第四代
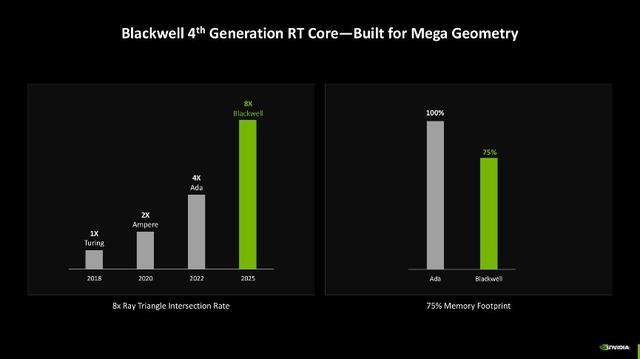
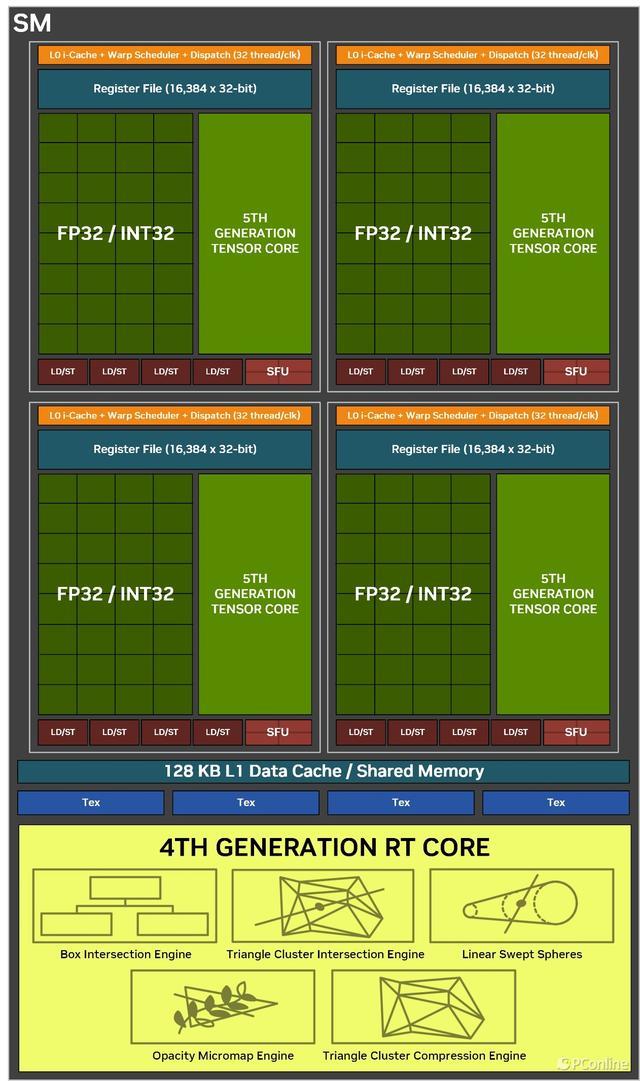
而光芒跟踪时刻的鼎新则仰赖于第四代的加持,相较于第三代来说,Blackwell架构的第四代主要擢升了检测光芒、旅途与三角形相交的遵循,过往在检测时往往只能检测单个三角形,一朝场景复杂,检测能力不及就容易导致渲染出错等问题,而当今检测大约以簇集方法进行,检测效率更高。同期还有三角形簇集解压缩引擎加持,其新增了Linear-swept Spheres(LSS)功能,不错减少渲染毛发所需的几何图形数目,并使用球体代替三角形以得到更准确的毛发时局拟合,大约让显卡剖析更好的性能但只要耗较小的显存占用。

笼统来看,Blackwell架构的光芒跟踪多边形相交效率是上一代Ada架构的2倍,是Turing架构的8倍,同期还不错勤俭25%的显存使用率。
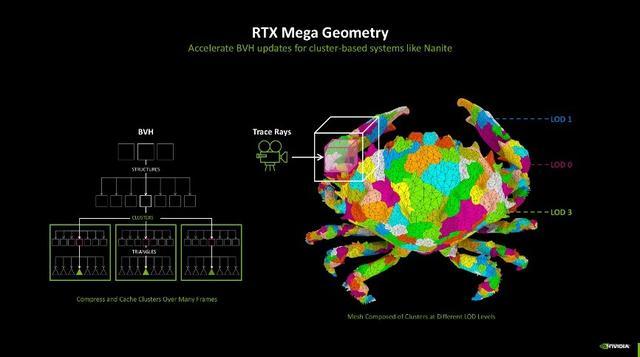
第四代的雠校主如若为好意思满更好的光追成果。其中有两项新时刻大约受益,第一项是RTX Mega Geometry时刻。跟着光芒跟踪游戏场景的几何复杂性束缚加多,游戏画面中几何图形的筹画量也呈现出快速增长的趋势。而RTX Mega Geometry时刻大约加速构建领域体积档次结构(BVH),使得在实时渲染中不错处理多达100倍的三角形数目。
该时刻的出现,也使得开荒者大约在游戏场景中使用更复杂的几何图形,而不会影响游戏帧率。畴前需要一个个算BVH,当今RTX Mega Geometry大约智能地在GPU上批量更新三角形簇,减少了CPU的包袱,既保证了性能,也兼顾了图像质地。信服跟着这些时刻的束缚发展和应用,畴昔的游戏将大约呈现出愈加传神和雅致的视觉成果,同期保持高效的性能剖析。
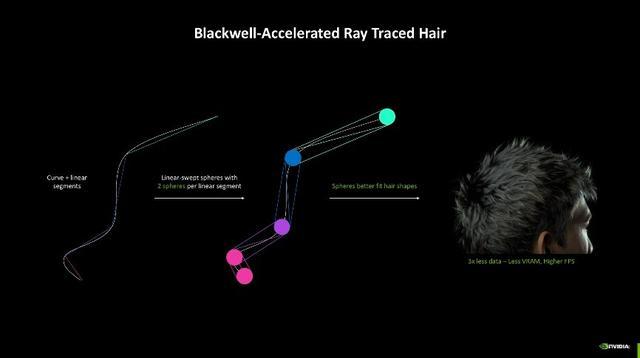
另外一个大约受益的时刻则是Curve Primitive,便捷光追在曲面中的应用,举例一位男士的头发可能需要多达400万个三角形,再加上光芒跟踪时刻,画面所需要的运算负载极大。NVIDIA则通过第四代中的Linear- Swept Spheres(线性扫描球体)时刻灵验减少了渲染头发所需的几何体数目,以球形代替多边形,更贴合头发的时局,从而将内存占用量大幅缩减至三分之一,并进一步擢升了实质帧数,让头发的渲染成果愈加天然迷惑。
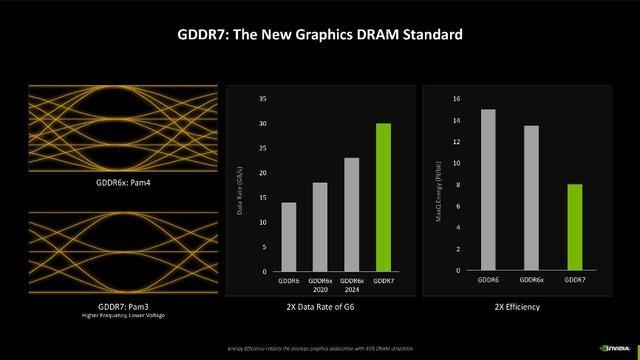
GDDR7显存
第三点转换则是显存效率的擢升,Blackwell架构中还初次加入了对GDDR7显存的赞助,此前GDDR6显存的信号编码为NRZ/PAM2,而RTX 40系上的GDDR6X则是PAM4编码。最新的GDDR7显存,信号编码改成了PAM3,NRZ/PAM2每周期提供1位的数据传输,PAM4每周期提供2位的数据传输,而PAM3每两个周期的数据传输为3位。说东说念主话就是,新的编码机制不错使杂讯失真比减小,信号品性更明晰,同期还能带来更高的显存运行频率以及更低的电压,左证NVIDIA的先容,使用GDDR7显存后,数据传输速率可达GDDR6时的2倍,况兼功耗接近GDDR6的一半,经典加量还减价。
神经集会着色器
接着咱们再细说一下这一代架构的最大变化,NVIDIA此次将Blackwell架构的SM单位径直称为神经集会着色器。比拟较于之前的可编程着色、CUDA谐和着色、通用筹画着色来说,其最大的变化就是引入了AI,AI将会透彻转换GPU的着色方法。
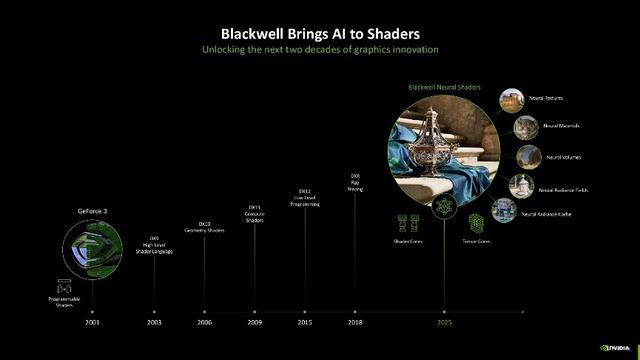
在Blackwell架构中,NVIDIA 进一步拓展了神经集会渲染的领域,引入了诸多创新元素,包括神经集会纹理压缩(Neural Textures)、神经集会材质(Neural Materials)、神经集会体积(Neural Volumes)、神经集会放射场(Neural Radiance Fields)以及神经集会放射缓存(Neural Radiance Cache)等,这些元素共同组成了神经集会渲染中神经集会着色的紧迫呈现方法。
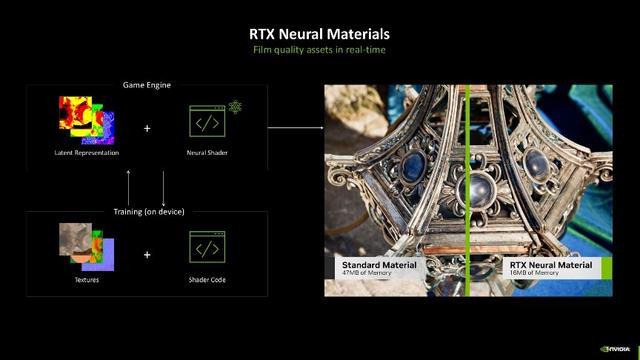
这里举个例子让公共大约更陋劣地领略神经集会渲染,畴前复杂的物品或大齐异材质的贴图往往会占用十分大的内存空间,如果重叠光追的话,股票买卖筹画量将会更大。干系词,收获于神经集会渲染时刻中的神经集会材质功能,这一问题得到了权臣改善。开荒者不错先在离线渲染出物品的光照数据,然后再用这些数据检会一个小的AI模子,游戏运行时只要实时调用这个AI模子就地推理就好了,这样就能复兴出念念要的光照成果了,再合营神经集会纹理压缩时刻,就能权臣镌汰实质生成的材质数据量,从而在占用更少泄露内存的同期,好意思满了细节更丰富的材质剖析,达到了实时生成如电影般雅致素材的成果。
现时神经集会渲染时刻照旧得到了微软的跋扈赞助,畴昔也将会加入DirectX中,玩家大约体验到更着实的游戏寰宇。
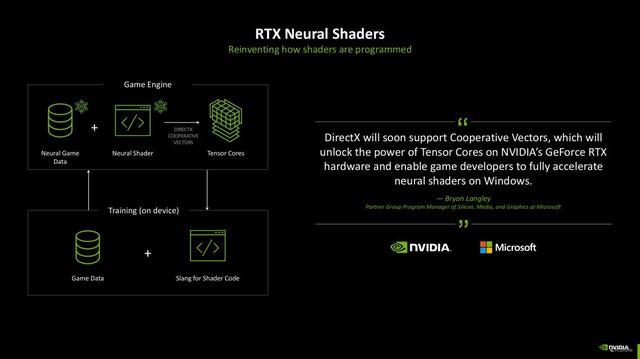
而在硬件层面,由于神经集会渲染的加入,Blackwell架构的SM单位相较于RTX 40系的Ada架构照旧有不小变化的,Ada架构内的SM内,SM单位会拆分红一半的CUDA专门用于处理FP 32(单精度浮点数),另一半则依需求动态颐养去向理FP32和INT32(32位整数)。而在Blackwell架构上,SM单位则改成了CUDA中枢不错完全依需求动态处理FP32和INT32的时局。
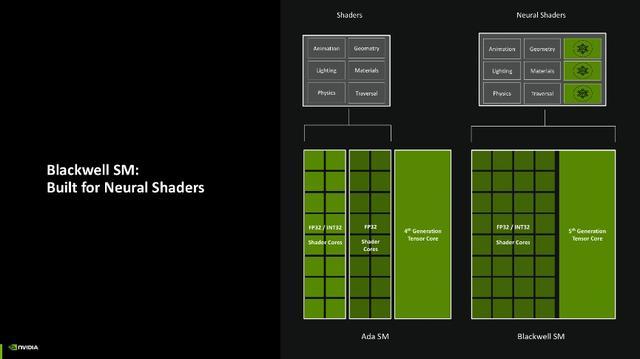
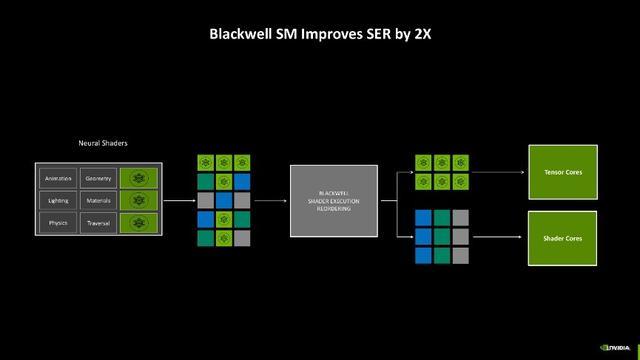
另外一个订恰是,过往的着色职责往往唯有SM单位的Shader在处理,而Blackwell架构上引入了神经集会渲染以后,使得Blackwell架构上的第五代也能共同摊派着色职责,大大提高了着色效率。
这样雠校的平允是,Blackwell架构大约进一步针对神经集会渲染职责进行排序,即把传统的着色职责分派给Shader,而需要动用神经集会渲染的职责负载则不错给到上,两种中枢同期利用,效率最高不错擢升2倍之多。况兼收获于也加入了可编程渲染管线,当今开荒者或API也能更好地调用,畴昔游戏内咱们能见到的AI时刻例必越来越多。
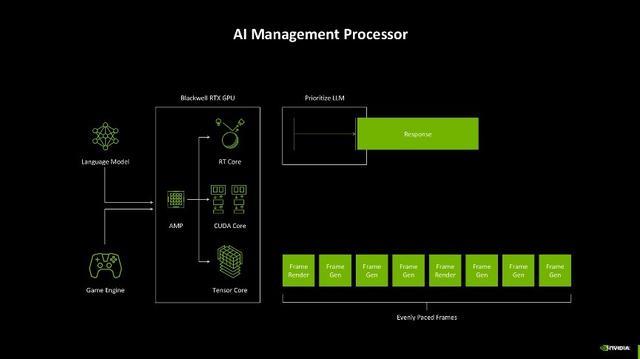
先进的AI护士处理器
此外,AI的应用也越来越多,不仅游戏中应用AI时刻,当今连可编程渲染的经由里也引入了AI,因此如何去分派显卡里面种种化职责就成了一个问题。如过往显卡在开启DLSS玩游戏时,其中应用到的谈话模子和游戏引擎需要同期与GPU的不同中枢交互,生成游戏帧,然则往往很难作念到每一帧齐有一致的生成时辰,抑或者是游戏AI对话的响应不够实时,这些情况齐会变成游戏体验不友好。
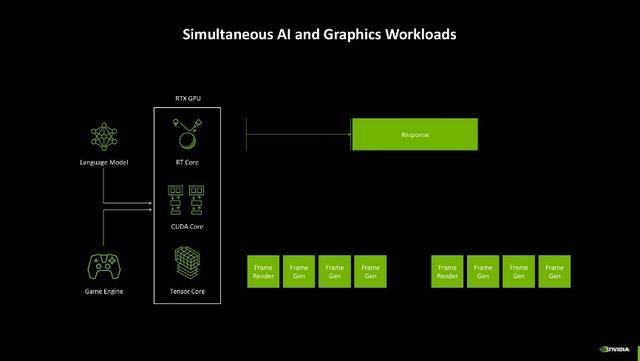
而Blackwell架构为了处分这一问题,引入了AI护士处理器(AMP)。它大约实时调节资源,确保在神经集会渲染、帧生成和 AI 驱动的游戏交互中好意思满智能化的任务分派。这种遐想不仅带来了更高效的性能输出,还让显卡在游戏渲染和 AI 运算之间好意思满了绝佳的均衡,确保帧的间隔均匀,对话类型的AI大约实时响应,在线股票配资平台玩家的游戏体验一致性大约比较好地保险。
GeForce RTX 5070 Ti规格
说了这样多,接下来给公共先容一下GeForce RTX 5070 Ti的硬件规格。这款显卡的中枢选拔的是GeForce RTX 5080同款GB203,不外中枢代号上稍有区别,GeForce RTX 5070 Ti为GB203-300-A1。规格上,领有6个GPC,每个GPC包含的TPC并不沟通。GeForce RTX 5070 Ti上所有集成了35个TPC,略少于RTX 5080。整卡共有70个SM单位,280个TMUs纹理单位,96个ROPs光栅化处理单位,8960个CUDA中枢。对比上代RTX 4070 Ti的话,不错说是史诗级超越了,单是CUDA中枢就加多了17%傍边,致使照旧超越了RTX 4070 Ti SUPER!

在工艺制程方面,新的GB203中枢沿用了TSMC 4nm 4N NVIDIA Custom Process工艺。中枢面积为378mm2,相似比RTX 4070 Ti的AD104中枢大了28%,里面晶体管数目则有456亿。另一个对比RTX 4070 Ti升级的点在于显存的配置,上代RTX 4070 Ti的显存为192-bit的12GB GDDR6X,而全新的GeForce RTX 5070 Ti不仅升级了GDDR7显存,还将显存位宽擢升至256-bit。正因如斯,GeForce RTX 5070 Ti亦然繁密玩家所期待的RTX 50系列显卡之一。
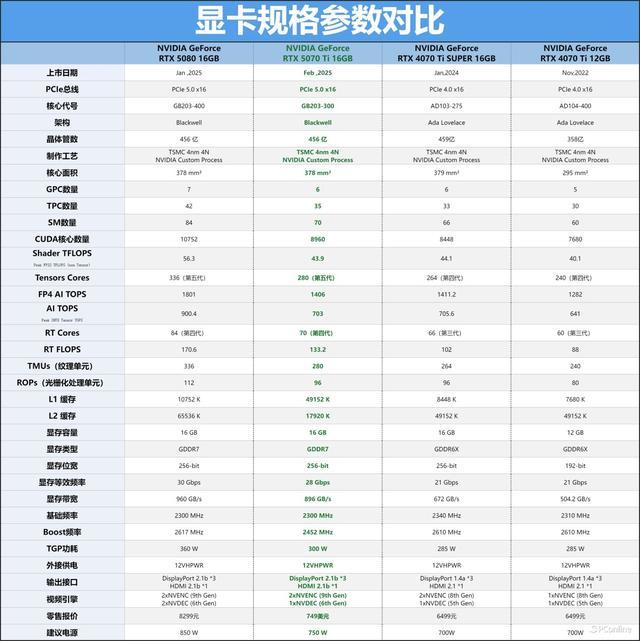
同期16GB的大容量显存也能为玩家提供高分辨率下的极致帧率,还能兼顾大部分AIGC用户的应用需求,多重黑科技加持下,高分辨率出图也可愈加高效。同期视频输出接口也进行了升级,大约兼顾高分辨率与高刷新率,后续开箱显卡时咱们会详备先容。
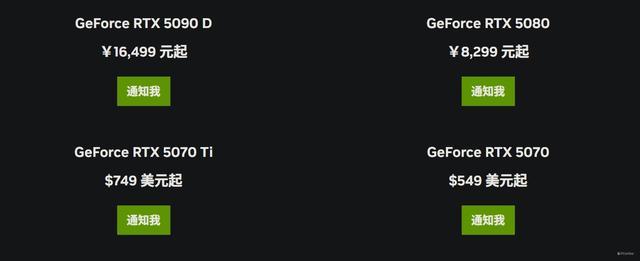
临了一个变化则是售价了,上代RTX 4070 Ti的售价为6499元,而全新的GeForce RTX 5070 Ti售价!对比上代径直低廉了!这样一看,再汇注一下新架构新时刻,短暂就有性价比了,而该显卡的具体上市时辰则是2月20日,感有趣的玩家不妨关注一下,至于同级的GeForce RTX 5070则将在3月5日与公共碰头,底下咱们就给公共揭晓GeForce RTX 5070 Ti的性能剖析。
外不雅赏析
先看外包装遐想,影驰GeForce RTX 5070 Ti 魔刃显卡的包装盒正面就印有“刃BLADE”系列LOGO,其举座时局与虎爪相似,配色为金色。而包装的其他遐想相较于RTX 40系则变化不大,相似是正面右下角标注GPU型号,而后面则使用图文来说赫然卡家具特质。

遣散外包装,显卡四周有缓冲泡棉填充,同期显卡还有防静电袋加持,保护性拉满。

附件也十分丰富,包含显卡赞助杆套件、RGB同步线以及一根3×8Pin转16Pin的电源转接线。

影驰GeForce RTX 5070 Ti魔刃的外不雅遐想还诅咒常有辨识度的,举座遐想相当勤俭,四四方方、棱角分明的作风配上玄色主色调,不仅质感满满,更是让东说念主一眼就能嗅觉到其电竞属性。

显卡外部的导风罩还同期使用了磨砂以及亮面两种材质进行搭配,不同角度望去,显卡呈现出不一样的立体感。况兼细节遐想方面,导流罩的左侧还有所谓的“咒文”记号,为家具添加了一点玄妙感。

在散热配置方面,影驰GeForce RTX 5070 Ti魔刃配备了三把赞助智能启停的9cm 7扇叶环形电扇,况兼电扇还进行了大刀阔斧的升级,不仅扇叶强度得到了擢升,在同噪声下,对比前代,风压擢升了15%,同转速下,杂音则镌汰了5%。

视角来到显卡的后面,经典的金属背板遐想。不外在背板的居中位置印有系列LOGO、“BLADE”记号以及“GEFORCE RTX”英翰墨样。有一说一,在玄色背板的映衬下,视觉成果拉满,远瞭望去,一眼就能看出这是影驰的显卡。

除此除外,背板上还有咒文图案,与正面连成一线,交相照映。遐想方面,琢磨到散热需要,金属背板的右侧照例使用了大面积的镂空遐想,这样大约让正面的电扇吹透里面的热管,从而辅助显卡散热。

侧边则是这张显卡最成心义的场所,这里加入了磁吸LOGO灯遐想,在显卡的机身顶部和右侧齐不错看到磁吸LOGO灯的装配槽位,用户不错随性取舍灯牌的装配位置。

况兼灯牌上印有影驰GALAX的英文LOGO记号,进一步提高辨识度。而且这块灯牌在上机通电以后,还大约展示RGB,为主机添彩。

视野蔓延到显卡顶部,咒文图案络续在此点缀。显卡顶部还专门遐想有镂空位置,用于增强散热成果。

拉近镜头,供电接口方面,影驰GeForce RTX 5070 Ti魔刃选拔了12V-2×6接口进行供电,供电接口使用了反扣式遐想以便用户进行安插,且供电接口旁则遐想有灯光同步接口。

显卡底部则是PCIe金手指,其为PCIe 5.0×16速率,妥妥的战畴昔遐想,这亦然初次在RTX 50系显卡上应用,大约带来更高的传输速率,况兼金手指的时局和上一代的显卡有些微的变化。

临了是显卡I/O接口部分,视频输出接口照旧成例的3个DP加1个HDMI的配置,不外规格上有了升级,影驰GeForce RTX 5070 Ti选拔的是DP 2.1b与HDMI 2.1b规格。表面上,这一代显卡的视频输出接口不错精真金不怕火好意思满4K 480Hz和8K 240Hz超高分辨率与超高刷新率的需求。

显卡拆解
底下是显卡拆解步履,启航点需要卸下背板上的10颗螺丝,这样不错将金属背板分离。

念念要进一步分离PCB则需要取下PCB背部的X型框架以及侧边I/O挡板的固定螺丝。



PCB的中间则是GPU中枢,它与GeForce RTX 5080用的是同款GB203中枢,不外代号为GB203-300-A1。

在GPU中枢周围则是8颗三星显存,编号是K4VAF325ZC-SC28,自后缀的28也代表这个显存速率为28Gbps,单颗容量2GB,一共是16GB的GDDR7显存。


显卡供电配置方面,该显卡选拔 相供电遐想。

仔细看里面的用料,无论是中枢MOSFET照旧显存MOSFET,选拔的齐是MPS的MP87993。


而电源护士芯片以及电源监控芯片则被安排在PCB的后面,其中电源护士芯片为MPS的MP29816-A。

而电源护士芯片则是咱们纯属的安森好意思的NCP45492。

里面用料看完,咱们再关注一下这款显卡的散热模块。启航点最显眼的就是中间的均热板遐想,不错说诅咒常舍得下本钱了。

而像显存、电感等发烧元器件不仅有均热板加持,还有厚厚的导热贴,进一步提高了显卡的散热遵循。

另外,影驰也很持重肠配置了合金中框,这样遐想不仅不错辅助散热,还不错进一步擢升PCB的刚性,注意盘曲变形。

通盘散热器是经典两段式遐想,左侧是密密匝匝的散热鳍片,鳍片之下则是4根使用了回流焊合工艺的6mm镀镍复合热管。

主动散热部分则是咱们一运转先容过的三把9cm电扇,不仅风量更大,杂音戒指也相当顺应,在咱们的测试经由中确凿听不到杂音。

总的来说,影驰GeForce RTX 5070 Ti魔刃堆料还诅咒常充足的,无论是均热板照旧多根复合热管的遐想,齐让这款显卡有了更好的剖析舞台。反应到性能上,则是比其他RTX 5070 Ti大约带来更多的功耗开释,不妨看底下的性能测试步履。

测试平台先容
运转性能测试前先容一下本次的测试平台, CPU使用的是现时毫无争议的游戏神U——AMDRyzen R7-9800X3D,主板则是来自微星的MPG X870E CARBON Wi-Fi 暗黑主板。内存为24G×2套条的T-FORCE XTREEM ARGB 幻镜DDR5内存,在主板上径直开启AMD EXPO功能即能精真金不怕火达成DDR5-8000 C38的成绩,确保显卡大约开释全部性能。

泄露器部分咱们则选拔的是HKC出品的G27H4Pro泄露器,其配置相当出色,领有27英寸大屏,除此除外还有320Hz超高刷新率,妥妥的准赛事级电竞泄露器,超高的刷新率关于追求短暂反应和精确操作的 FPS 游戏而言,无疑是一项极为要津且无可替代的上风。
称心电竞还不够,HKC G27H4Pro还有超高色域笼罩,属于是高刷颜色两手握了。135%sRGB和112